Subspace Clustering
For the generation of clusters, often a part of features are relevant, especially for the high dimensional data. From this point of view, a number of clustering methods are proposed to find clusters in different subspaces within a dataset.
Two Perspectives
- There exists subspace in data, so we search for the most representative feature subsets.
- As there are clusters in different subspaces, features are more dense in each subspace cluster. Instance within a cluster can be represented by other instances within the same cluster. From this perspective, we seek to learn a representation of data, which yield X=XC.
The first perspective motivates many data mining algorithms (see survey by Parsons L. et. [1]). But due to the complexity of those algorithms, they can not handle large scale datasets. Recently, the majority of subspace clustering researchs are considering from the second perspective. By making different assumptions: the sparsity or the low-rank property, these methods can be generally divided into sparse subspace clustering [2] or low-rank subspace clustering [3].
Note that learning a representation of itself in the form of X=XC is very simple. To improve this model, a sort of algorithms consider using dictionary learning in subspace clustering, to learn a clean dictionary and an informative code, which yield X=DC. That is a big topic, see survey by Zhang Z. etc. [4] and survey by C Bao. etc [5].
Paper Sharing: Deep Adaptive Clustering [6]
Motication
In image clustering, existing methods often ignore the combination between feature learning and clustering.
Method
DAC is based on deep network, so we just give the flowchart. Firstly, a trained ConvNet is given to generate features, which guarantee the basic capacity of separation. Based on the learned features, traditional similarity learning is applied to find similar pairs and dissimilar pairs, similar to must-link and cannot-link in network mining. After obtaining those constraints, DAC goes back to train the ConvNet. That is one iteration.
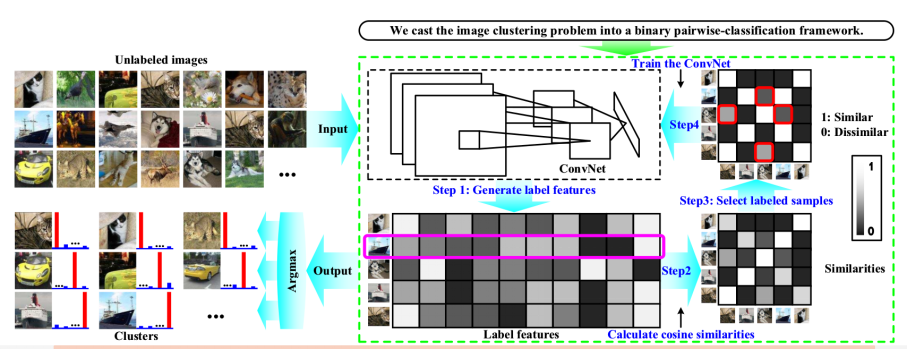
The hint of DAC are that:
- It adopts a classification framework for clustering.
- The learned features tend to be one-hot vectors by introducing a constraint into DAC. Thus clustering can be performed by locating the largest response of the learned features.
Doubts
The performance of DAC is strongly dependent on the initialization of ConvNet. It is learned by another method.
Others
There are other ideas that using “supervised” model to clustering task. For example [7]
References
[1] Parsons L, Haque E, Liu H. Subspace clustering for high dimensional data: a review[J]. Acm Sigkdd Explorations Newsletter, 2004, 6(1): 90-105.
[2] Elhamifar E, Vidal R. Sparse subspace clustering[C]//Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. IEEE, 2009: 2790-2797.
[3] Vidal R, Favaro P. Low rank subspace clustering (LRSC)[J]. Pattern Recognition Letters, 2014, 43: 47-61.
[4] Zhang Z, Xu Y, Yang J, et al. A survey of sparse representation: algorithms and applications[J]. IEEE access, 2015, 3: 490-530.
[5] Bao C, Ji H, Quan Y, et al. Dictionary learning for sparse coding: Algorithms and convergence analysis[J]. IEEE transactions on pattern analysis and machine intelligence, 2016, 38(7): 1356-1369.
[6] Chang J, Wang L, Meng G, et al. Deep Adaptive Image Clustering[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 5879-5887.
[7] Liu H, Han J, Nie F, et al. Balanced Clustering with Least Square Regression[C]//AAAI. 2017: 2231-2237.
Categories: DM