Motivation
Diversity in retrieval tasks, reduces redundancy, showing more information.
e.g. A set of documents with high topic diversity ensures that fewer users abandon the query because no results are relevant to them.
In short, high diversity will cover more needs for different users, though the accuracy may not be good.
Preliminary
Candidate set: x = {x_i}, i = 1 … n
Topic set: T = {T_i}, i = 1 … n; T_i contains x_i, different topic sets may overlap.
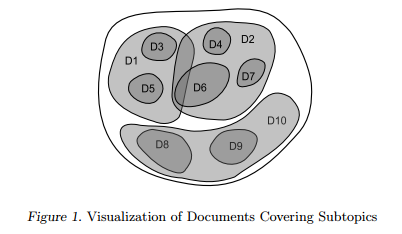
Idea
The topic set T is unknow, thus the learning problem is to find a function for predicting y in the absence of T.
Is T the latent variable ??
– In general, the subtopics are unknown. We instead assume that the candidate set contains discriminating features which separates subtopics from each other, and these are primarily based on word frequencies.
The goal is to select K documents from x which maximizes subtopic coverage.
Keypoint: Diversity -> Covering more subtopics -> Covering more words
Method Overview
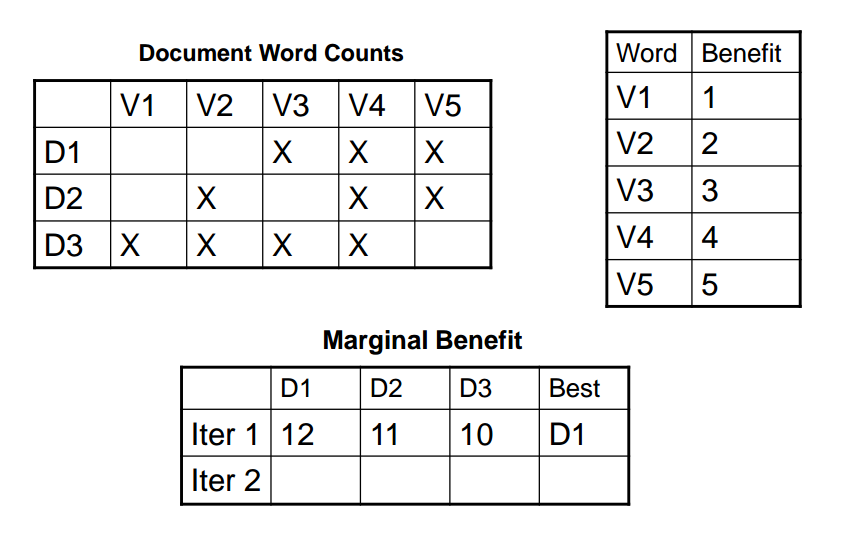
D1, D2, D3 are three documents, V1, V2, … , V5 are words.
weight word importance (more distinct words = more information)
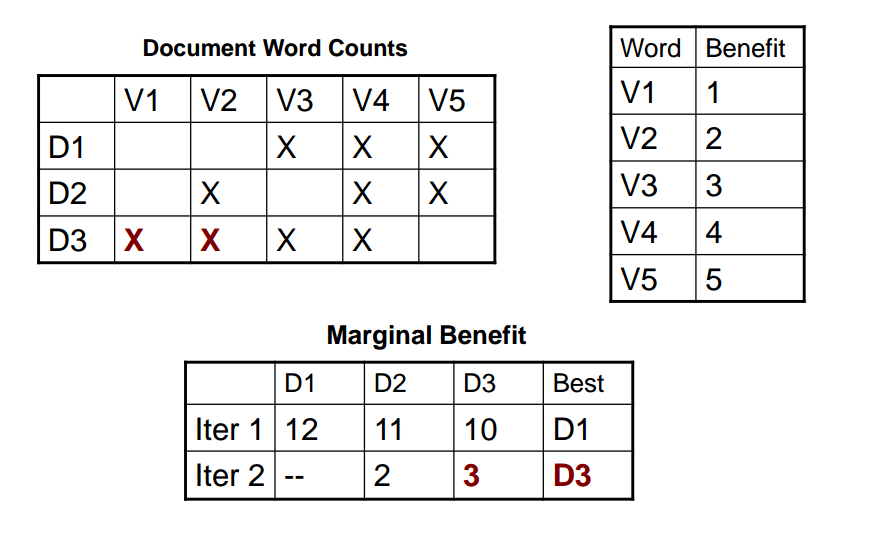
After D1 is selected in the first iteration, which covers V3, V4, V5;
In the second iteration, we only focus on V1 and V2.
Remark:
– Feature space based on word frequency
– Optimizes for subtopic loss (Structural-SVM)
The process of this model is sophisticated. Feature space is based on word frequency, and it further divided into “bag of words” (subtopic).

From my point of view, a reason should be: each document has too many words, so dividing document into subtopics is reasonable, and this approach will reduce the overlapping between subtopics of different documents.
In each iteration, we learn the most representative subtopic, then choose the related document until we get K documents.

Remark: Structural-SVM repeatedly finds the next most violated constraint until set of constraints is a good approximation.
Comments
This paper is very interesting.
My doubts are:
- Can frequency of word reflect the true relevance of the document to a certain topic?
- How to find subtopics?
Further Reading
Learning to Recommend Accurate and Diverse Items [WWW’17]
Categories: DM